The Powerbase Vision
The Short Version
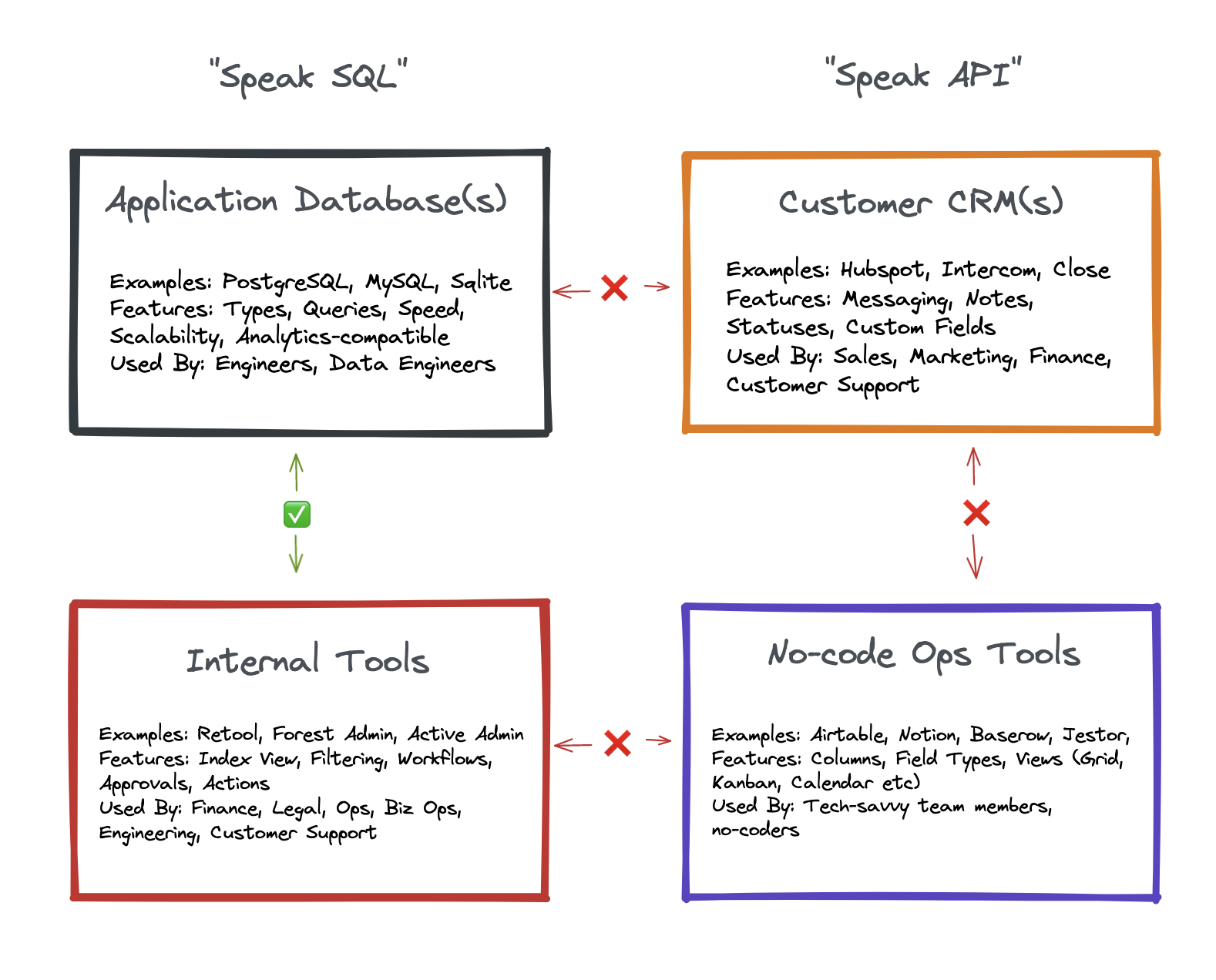
All Software Supported Businesses use the same "stack" of tools to operate - those tools being classifiable into four main categories - 1. Application Database(s), 2. Customer CRM(s), 3. Internal Tool(s), and 4. No-code Ops tool(s)
The data stored in these systems is fundamental to how these businesses operate. But it is siloed and disconnected. Huge resources are spent trying to connect it and pass data between systems.
All four categories listed above use by the same technology behind the scenes to store data - the Relational Database.
Relational databases were built to be interoperable. It should be possible to use a single, universal interface, to browse, manage and interact with all the data across all the systems in a consistent, seamless way.
But currently, that's not the case, for two reasons:
External systems don't currently speak the same language as internal ones. They "Speak API" while internal tools "Speak SQL".
There is no product that supports browsing, linking and interacting with data stored across systems in this way.
The Long Version
Part One: The Software Supported Business
Most "tech companies", when stripped back, use technology to do the same thing. They provide interfaces that a customer interacts with, which send data into a series of relational databases. They then hire staff to sit on the other side of those databases, and use the information to enhance and support the customer's experience, and to increase their bottom line.
These staff are generally split across a number of departments - marketing, sales, customer success, and support to name a few. As a company grows and operational complexity increases, the departments begin to operate independently, each choosing their own set of software to increase their efficiency.
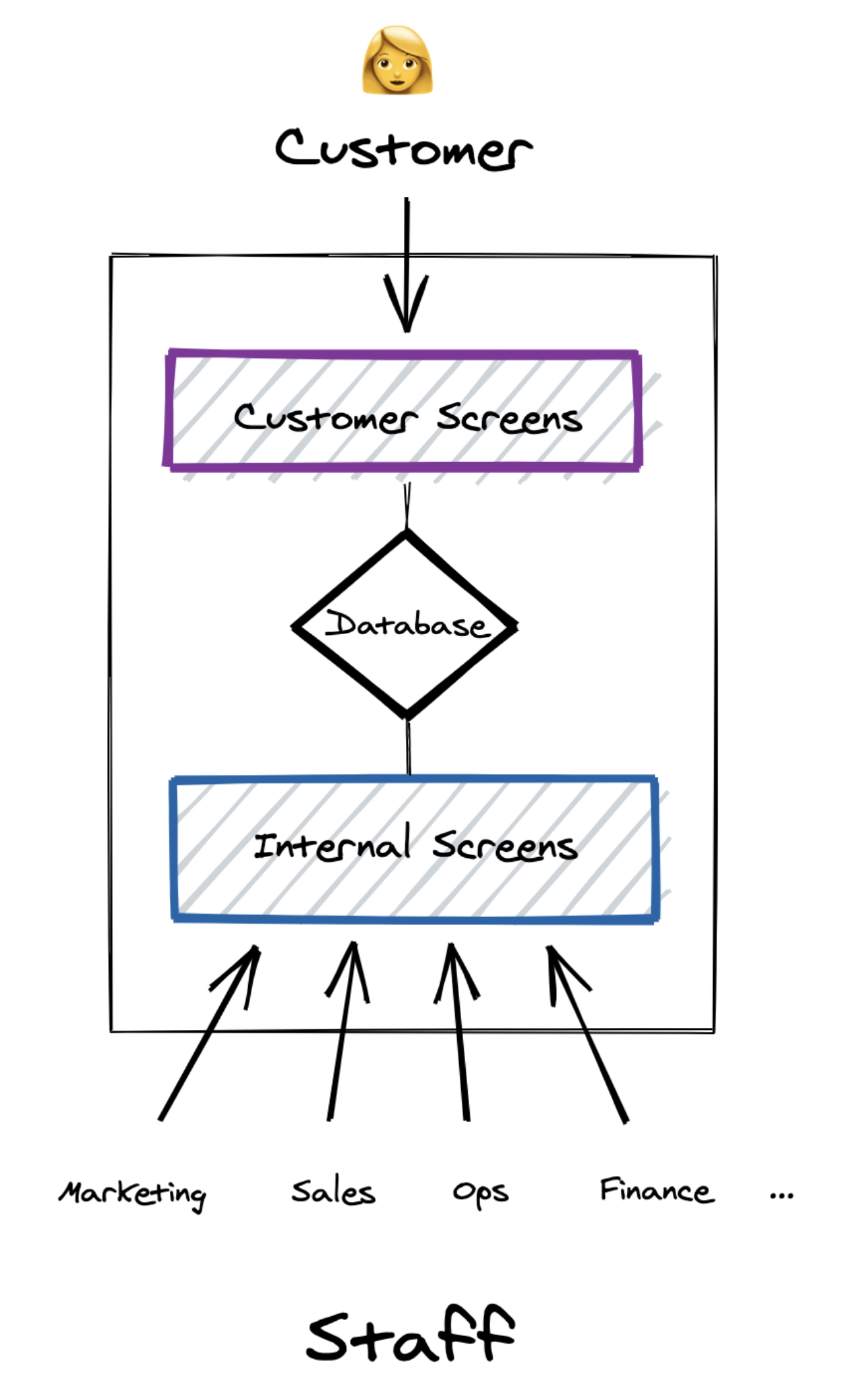
This leads to data silos, where customer data needed by one internal department, flows into the tool used by that department. But when the customer interacts with another department, that team does not have the same data.
This in turn leads to a degradation in customer experience, as customers are forced to repeat themselves in order to re-build context every time they speak to someone new in the same organization. Anyone who has ever contacted support within a telco or government agency will be familiar with this frustration. Customers don't, and shouldn't, care about how a company is configured internally. As far as they're concerned, they're transacting with a single entity, and want their experience to reflect that.
Over time, various methods and tools are used to sync data between tools to solve this problem. Normally, these methods create a new set of problems: System limitations mean only certain data can be sent from one place to another. Incomplete information leads people to duplicate the same data in multiple systems, creating the "which system is most up to date?" problem. These problems compound, causing people to doubt the reliability of the data they're seeing. Add to that sync delays, duplication issues, the list goes on...
Whilst I've described the above problems mainly from a customer's perspective, there are also non-customer-facing internal functions for whom data consistency and integrity are equally critical. For these functions, it could be argued that a non-trivial part of their entire purpose is to wrangle data from various sources into coherency. For example - the finance team, who spends time collecting and reconciling financial information from various sources, or the data team, who spend time transforming and reconfiguring data so that it can inform and optimize other parts of the organization.
The problem set described above is currently most synonymous with "tech" companies, but in time, we consider it inevitable that most, if not all businesses will operate in a similar way. For that reason we prefer the term "Software Supported Business" to describe a business configured like this.
The "Big Four"
As mentioned above, Software Supported Businesses are almost always built on top of the same "stack" of tools, namely:
The Application Database is where the engineering team sends the customer data and the data needed by the product.

Internal Tools are usually built by engineering teams to empower other internal teams like sales or customer support. They're used to perform common admin-only actions. For example: Creating a demo account, Canceling an order, Merging duplicate accounts, Reseting a user's password etc.

Customer CRMs are used by internal teams to manage operational workflows related to customers. Usually there's a sales CRM, and quite often there's one for customer support too, although these are often different products.

No-code Ops Tools like Google Sheets and Airtable are generally used either as internal collaboration and productivity tools, or to manage operational workflows that track customers through a particular workflow.

If you look closely, you'll notice some similarities between each of the four categories, namely:
Most of the important functionality across all four can be represented and modelled as some combination of the same three concepts: tables, attributes and relationships.
As a result, many of the interfaces used to browse the data are the same - the "list" view, the "single record" view, filtering, saved searches, and many more.
In all four categories, there is the concept of a "User" or a "Customer", as well as the concept of an "Internal team member" or "Employee".
What's peculiar is that despite having so many similarities, the data stored in each of these systems is completely siloed. Aside from the application database and internal tools, which both "Speak the same language", it's difficult to get the other systems to communicate in a low-setup, real-time, connected way. This is a problem because there are hundreds of scenarios in which data from one system is needed to support the functionality of another system.
One approach to solving this is the "event-driven" model - a piece of data enters one system, which triggers an event that sends the same data to another system, and the data gets "passed around", removing any notion of a "single source of truth". This approach is quite easy to understand, and the companies who have figured out how to offer it as a product, such as Zapier, have thus done very well.
The other common approach is the "API integration" model. This requires having an engineering team write code that tells one system where to send data into another system. This approach tends to be more robust than the no-code automation tools like Zapier, but is very costly to implement and is still prone to break in unpredictable ways.
Why does this matter?
As former CTO of two operationally intensive software-supported businesses, I've spent a lot of time thinking about how best to solve these problems. My naive expectation (before becoming a CTO) was that my job would be to oversee the creation of the customer-facing products and experiences, but the reality was that a large amount of my team's time and resources were spent on facilitating internal operations and bridging the gap between our staff and our users, by building tools and piping data between the external systems that these teams used to do their jobs.
This ultimately meant my team was not as focused on customer problems as we wanted to be, and the customer's experience was not nearly as good as it could have been, had we been able to devote all our time and resource to it. This is true of the vast majority of Software Supported Business beyond a few dozen employees.
The reality is that once a Software Supported Business has figured out their core product or service, the next questions are: 1. How efficiently can we provide these products/services to our customers, 2. How can we improve our customers' experience when delivering, supporting and maintaining our products and services at scale, and 3. How can maximize our bottom line by building metric-driven feedback loops. In a digital environment, none of these things can be meaningfully addressed without first having data that is reliable, consistent, and accessible.
In a perfect world, teams could have a unified, real-time view of all their data across all their systems, whilst continuing to use the tools they're already using, and without needing an in-house data engineering team. This would both dramatically reduce the operational overhead to growing a Software Supported Business, and substantially improve the average customer's experience, allowing more teams to provide better products and services, to more customers.
What does this look like?
The Powerbase vision and roadmap is currently based upon the two problems mentioned at the beginning of this piece. Namely:
1. There is no product that supports browsing, linking and interacting with data stored across systems.
Powerbase is, first and foremost, a power tool for working with relational databases. It will allow you to browse, manage, and update data stored in any relational database, through an easy-to-use, intuitive interface.
2. External systems don't "speak the same language" as internal ones. They "Speak API" while internal tools "Speak SQL".
In order to be able to do (1) above, we first need to be make all data accessible in the correct format (for our purposes this is SQL). The infrastructure to enable this is the second key part of our technology roadmap.
We're almost ready to pull back the curtain on many of the features and functions we lay out above, but not quite. If any of this resonates with you, please leave your email address below and we'll keep you in the loop as we progress.
Powerbase
Copyright © 2021 Powerbase. All rights reserved.
Company
Made in Typedream